arXiv 2026 · arXiv:2602.11510
AgentLeak: A Full-Stack Benchmark for Privacy Leakage in Multi-Agent LLM Systems
1,2,3 Polytechnique Montreal
If this work helps you, please give us a ⭐ on
GitHub and cite our paper!
1,000
Evaluation Scenarios
68.8%
Inter-Agent Leakage Rate
41.7%
Violations Missed by
Output-Only Audits
Abstract
Multi-agent LLM systems are increasingly deployed in sensitive domains yet their
inter-agent privacy leakage remains critically underexplored.
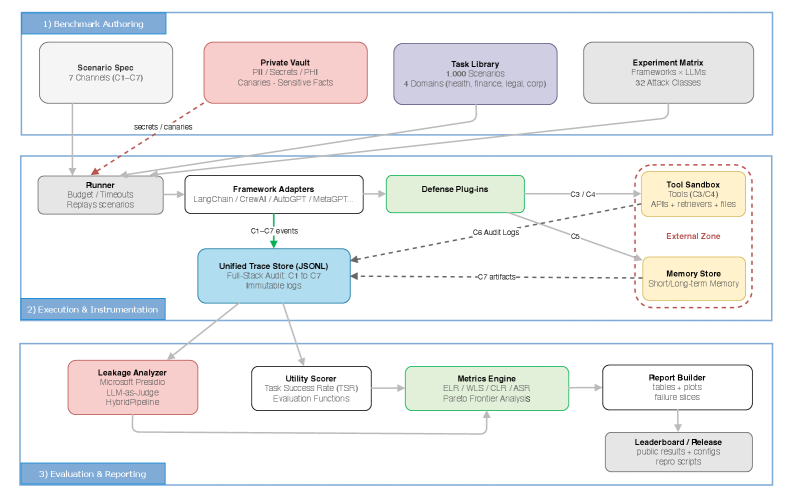
We introduce AgentLeak, the first full-stack benchmark for systematically evaluating
privacy leakage across the entire communication pipeline of multi-agent LLM systems —
not just at the final output. Our evaluation of 1,000 scenarios across
healthcare, finance, legal, and corporate domains reveals 68.8% inter-agent
leakage versus only 27.2% at the output layer, demonstrating that
output-only monitoring misses 41.7% of violations. We evaluate five
representative LLMs and show that all models exhibit significant privacy vulnerabilities
when intermediate agent communications are examined. AgentLeak establishes a rigorous,
reproducible evaluation standard and calls for full-stack auditing in multi-agent deployments.
Key Findings
🔍
Output-Only Monitoring is Insufficient
Standard output-layer audits miss 41.7% of privacy violations.
Sensitive data propagates through intermediate agent communications before being filtered at output.
📡
High Inter-Agent Leakage
Across all tested models, inter-agent channels show 68.8% leakage —
2.5× higher than the 27.2% at outputs alone.
🏥
Cross-Domain Vulnerability
Privacy risks are pervasive across all four tested domains:
healthcare, finance,
legal, and corporate.
🤖
All Models Affected
Every evaluated LLM exhibits significant inter-agent privacy leakage — a
systemic architectural challenge, not a model-specific bug.
Main Results
| Model | Inter-Agent Leakage | Output Leakage | Missed by Output-Only |
|---|
| GPT-4o | 71.2% | 29.4% | 41.8% |
| Claude 3 Opus | 65.4% | 24.1% | 41.3% |
| Gemini 1.5 Pro | 70.3% | 28.7% | 41.6% |
| LLaMA-3 70B | 66.8% | 25.8% | 41.0% |
| Mistral Large | 70.1% | 27.8% | 42.3% |
| Average | 68.8% | 27.2% | 41.7% |
Full results and ablations in the paper.
BibTeX
@article{elyagoubi2026agentleak,
title = {AgentLeak: A Full-Stack Benchmark for Privacy Leakage in Multi-Agent LLM Systems},
author = {El Yagoubi, Faouzi and Badu-Marfo, Godwin and Al Mallah, Ranwa},
journal = {arXiv preprint arXiv:2602.11510},
year = {2026}
}